
シンセティックデータの概念イメージ(出典:MIT Technology Review)
シンセティックデータとは何か?
シンセティックデータ(合成データ)とは、実在するデータの統計的特性を保持しつつ、人工的に生成されたデータのことを指します。実際のデータに基づいて作られるものの、特定の個人を識別できる情報は含まれていないため、プライバシーを保護しながらデータ活用を促進できるという大きな利点があります。
ガートナーは2025年のデータ/アナリティクスのトップトレンドとしてシンセティックデータを挙げており、「機密データの代替となり、データのプライバシーを確保するだけでなく、データのバリエーションを増やすことによってAI開発を促進できる」と評価しています。
シンセティックデータと生成AIの関係
シンセティックデータと生成AIは密接に関連していますが、異なる概念です。生成AIはコンテンツを作り出す技術であるのに対し、シンセティックデータは特に「データセット」の生成に特化しています。実は、多くのシンセティックデータは、GANs(敵対的生成ネットワーク)やディフュージョンモデルなどの生成AI技術を用いて作成されています。

GANによるシンセティックデータ生成の仕組み(出典:Acompany)
「シンセティック・データは、データのプライバシーを確保するだけでなく、データのバリエーションを増やすことによってAIの開発を促進できる。」— ガートナー
シンセティックデータ市場の急成長
シンセティックデータ市場は爆発的な成長が予測されています。複数の市場調査によると、2023年に約3.5〜4.3億米ドル規模だった市場は、2030年には17〜34億米ドルに達すると予測されています。年間成長率(CAGR)は30〜40%に達する見込みで、これは他のテクノロジー市場と比較しても非常に高い成長率です。
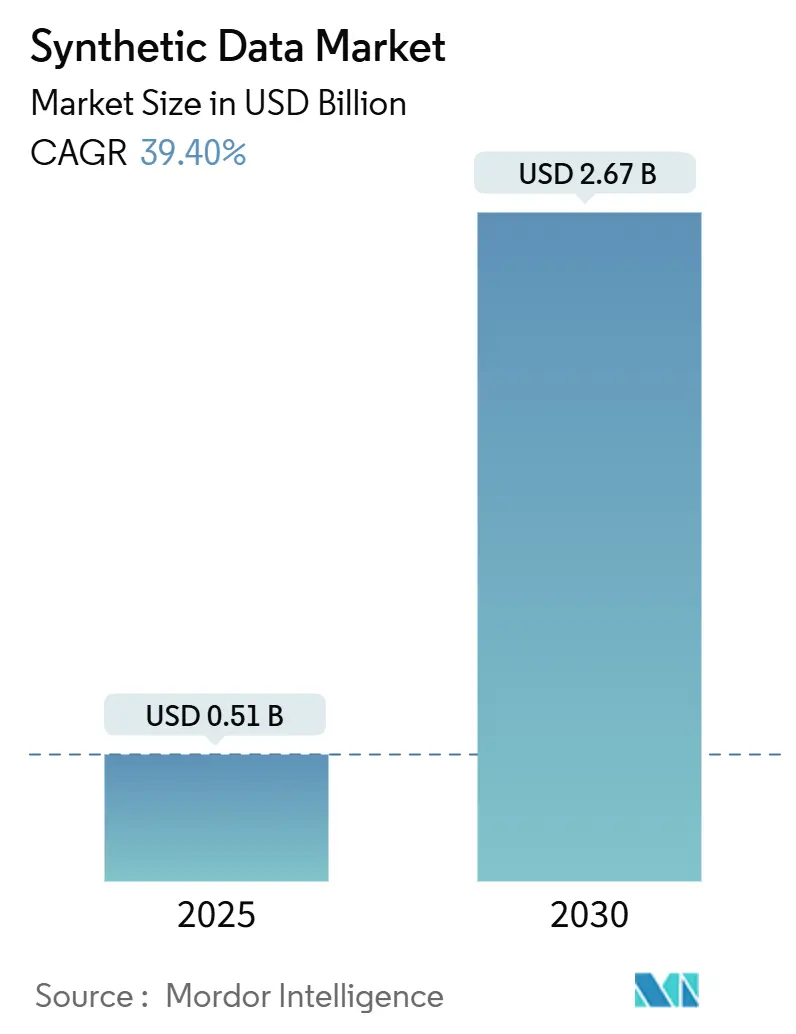
合成データ市場規模の予測(出典:Mordor Intelligence)
この急成長の背景には、以下のような要因があります:
- 世界的なデータプライバシー規制の強化(GDPR、CCPA、改正個人情報保護法など)
- AIモデル開発における大規模で多様なデータセットへの需要増加
- リアルデータ収集のコストと時間の制約
- クラウドコンピューティングとAI技術の進歩
- データ共有・流通のニーズ増大
業界別の採用状況
現在、シンセティックデータの採用が最も進んでいるのは以下の業界です:
| 業界 | シンセティックデータの主な用途 | 導入状況 |
|---|---|---|
| 金融 | 詐欺検出、リスク分析、シナリオテスト | 先進的 |
| ヘルスケア | 医療研究、医療画像、臨床試験 | 成長中 |
| 自動車 | 自動運転システムのトレーニング | 先進的 |
| 小売 | 顧客行動分析、在庫最適化 | 初期段階 |
| 製造業 | 異常検知、予知保全 | 成長中 |
シンセティックデータ生成の主要技術
シンセティックデータを生成するための技術は急速に発展しており、主に以下のアプローチが使われています:
1. 生成的敵対ネットワーク(GANs)
GANsは「生成器」と「識別器」の2つのニューラルネットワークを競わせることで、高品質なシンセティックデータを生成します。特に画像、音声、テーブルデータなどの複雑なデータタイプの生成に効果的です。

GANの基本構造(出典:Acompany)
2. ディフュージョンモデル
近年、Stable DiffusionなどのAIイメージ生成で有名になったディフュージョンモデルも、高品質なシンセティックデータの生成に応用されています。ノイズを徐々に取り除いていく過程でデータを生成するため、特に細部の表現に優れています。
3. 統計的生成方法
実データの統計的特性(分布、相関など)を分析し、それらを保持するようにデータを生成する手法です。金融データなどの数値データ生成に広く利用されています。
4. エージェントベースシミュレーション
複数の「エージェント」の相互作用をシミュレーションして、複雑な行動パターンやシステム挙動を再現するデータを生成します。都市計画や交通流シミュレーション、感染症の拡散モデルなどに活用されています。
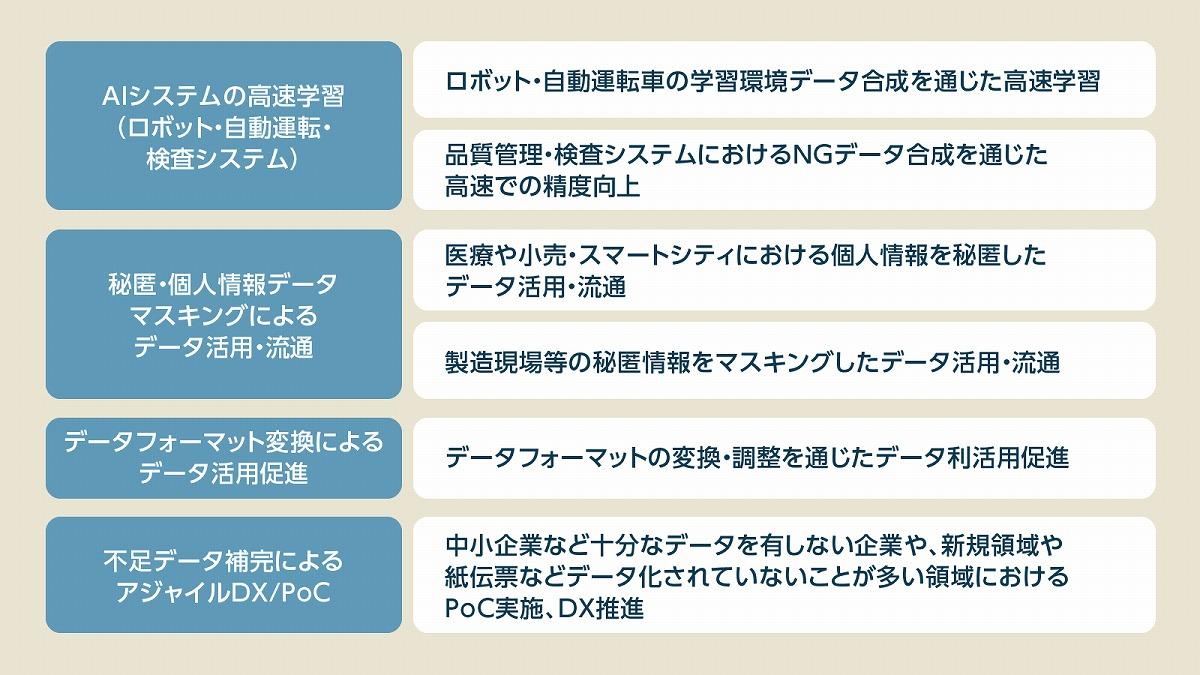
シンセティックデータの主要活用事例
2025年現在、シンセティックデータは様々な分野で革新的な活用が進んでいます。特に注目すべき事例を紹介します。
1. 金融業界:リスク分析と詐欺検出
金融機関は、シンセティックデータを用いてマネーロンダリングや不正取引のパターンをシミュレーションし、検出システムの精度向上に活用しています。実際の詐欺データは稀であり、バランスが取れていないため、シンセティックデータによる補完が効果的です。
ある大手銀行では、シンセティックデータを活用した詐欺検出AIの導入により、検出率が約25%向上し、誤検出(誤警告)が40%減少したという報告があります。
2. ヘルスケア:医療研究と個人情報保護の両立
医療分野では、患者の個人情報保護が最重要課題です。シンセティックデータは、実際の患者データの統計的特性を保持しつつ、個人を特定できない形で医療研究に活用されています。
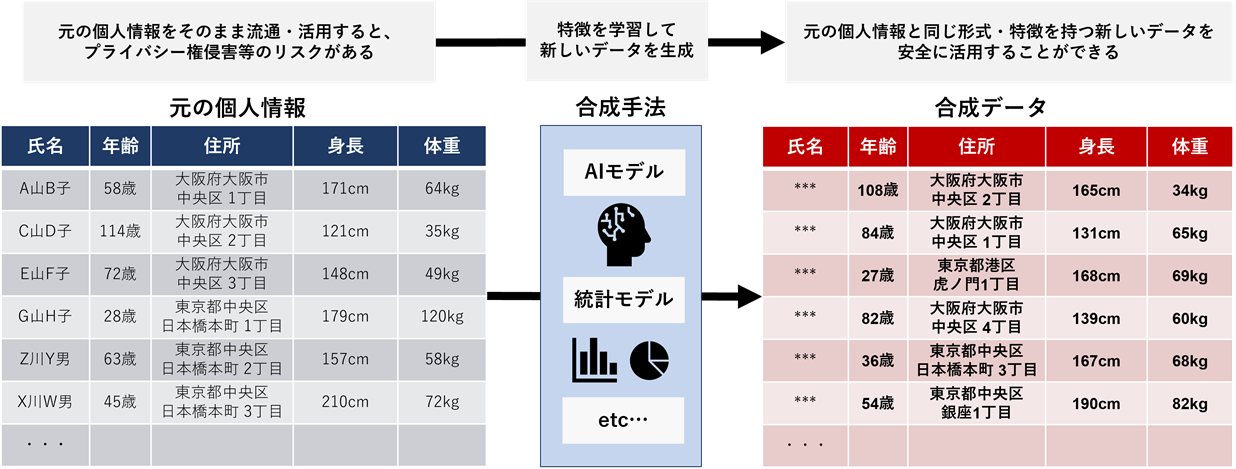
シンセティックデータによるヘルスケアデータ活用の概念(出典:日鉄ソリューションズ)
例えば、希少疾患の臨床試験データが不足している場合、既存の少数データからシンセティックデータを生成して研究を加速することができます。また、病院間でデータ共有が難しい場合も、シンセティックデータを介することで、プライバシーを保護しながら協力研究が可能になります。
3. 自動運転:安全なテストデータ
自動運転技術の開発には膨大なデータが必要ですが、稀なケースや危険な状況のデータを実世界で収集するのは困難です。シンセティックデータを用いることで、実際の道路で遭遇する可能性のあるあらゆるシナリオを安全に再現し、AIシステムをトレーニングすることが可能になります。
自動運転開発の最先端企業では、リアルデータとシンセティックデータを組み合わせたハイブリッドアプローチが主流となっており、開発コスト削減と安全性向上の両方に貢献しています。
4. マーケティング:消費者行動の予測
マーケティング分野では、限られた実データから消費者行動モデルを構築し、様々なシナリオでのシンセティックな購買行動データを生成して分析に活用しています。これにより、新製品の市場投入前にターゲット顧客の反応を予測したり、プロモーション効果をシミュレーションしたりすることが可能になります。
シンセティックデータのビジネス活用イメージ(出典:ビジネス+IT)
イプソスなどの市場調査会社は、合成データを活用した製品テストの革新的アプローチを提供し始めており、コスト削減と効率化を実現しつつ、人間の洞察を維持する方法として注目されています。
シンセティックデータ導入のメリットと課題
メリット
- プライバシー保護の強化:個人を特定できるデータを使用しないため、データ漏洩リスクやプライバシー侵害のリスクを低減
- データ量の拡大:必要なだけデータを生成できるため、少数派クラスの拡充やエッジケースの補完が可能
- コスト削減:実データの収集・クレンジング・ラベリングコストを削減
- アクセシビリティの向上:機密データへのアクセス制限を回避し、より多くの開発者や研究者がデータを活用可能
- バイアス制御:意図的にデータ内のバイアスを調整・除去してフェアなAIモデル構築が可能
課題と限界
シンセティックデータの活用にはいくつかの課題も存在します:
1. 品質と信頼性の確保
生成されたデータが実データの複雑な特性をどこまで正確に再現できているかは常に課題です。特に、複雑なドメイン知識を必要とする分野では、生成モデルの調整が難しく、専門家による検証が必要です。
2. バイアスの継承
シンセティックデータは元となる実データのバイアスを継承してしまう可能性があります。むしろ、不適切なデータ生成設計によって、既存のバイアスを増幅してしまうリスクもあります。
3. 法的・倫理的課題
シンセティックデータの法的位置づけはまだ明確でない部分があります。特に個人情報保護法との関係や、生成されたデータの知的財産権の問題は今後整理されていく必要があります。
日本では改正個人情報保護法における「仮名加工情報」や「匿名加工情報」との違いや、シンセティックデータの取り扱いに関するガイドラインの整備が進められています。
4. 標準的な評価手法の確立
シンセティックデータの品質を評価する標準的な指標や手法がまだ確立されていないことも課題です。実データとの類似性、プライバシー保護レベル、モデル性能への影響など、多角的な評価が必要とされています。
2025年以降のシンセティックデータ展望
シンセティックデータは今後、どのような発展を遂げるのでしょうか。専門家やアナリストによる予測をまとめました。
技術面での進化
- マルチモーダルデータ(テキスト、画像、音声、構造化データなど)を組み合わせたシンセティックデータ生成技術の発展
- 生成AIとシンセティックデータの融合による、より高度で現実的なデータの生成
- エッジAIにおけるシンセティックデータ活用の拡大(オンデバイス学習や連合学習との組み合わせ)
- 説明可能なシンセティックデータ生成アルゴリズムの開発
ビジネス面での発展
- 「Synthetic Data as a Service(SDaaS)」の普及と専門プロバイダーの成長
- 業界別・用途別の特化型シンセティックデータソリューションの登場
- データマーケットプレイスでのシンセティックデータ流通の活性化
- 大手クラウドプロバイダーによるシンセティックデータ生成ツールの標準提供
規制と標準化
- 各国でのシンセティックデータに関する法的枠組みの整備
- 品質評価や安全性に関する業界標準の確立
- プライバシー保護と実用性のバランスに関するベストプラクティスの共有
- 監査可能性と透明性を高める認証制度の創設

シンセティックデータの発展ロードマップ(出典:PwC)
日本企業にとってのシンセティックデータ活用のポイント
日本企業がシンセティックデータを効果的に活用するためのポイントを整理しました:
1. 明確な目的設定
シンセティックデータの導入目的を明確にしましょう。データ不足の解消なのか、プライバシー保護強化なのか、テスト環境の充実なのかによって、適切な手法や投資規模が変わります。
2. 段階的アプローチ
いきなり全面的に導入するのではなく、特定の用途や部門から試験的に導入し、効果検証を行いながら段階的に拡大することをお勧めします。
3. 専門知識の獲得
シンセティックデータ生成には、データサイエンスや機械学習の専門知識が必要です。社内人材の育成や外部専門家の活用を計画的に進めましょう。
4. プライバシー影響評価
シンセティックデータを生成・活用する際には、プライバシーリスクの評価を行い、再識別リスクなどを検証することが重要です。特に医療や金融など機密性の高いデータを扱う場合は慎重な対応が求められます。
5. ハイブリッドアプローチ
多くの場合、実データとシンセティックデータを組み合わせたハイブリッドアプローチが最も効果的です。両者の長所を活かした戦略的なデータ活用を検討しましょう。
まとめ:シンセティックデータが開く未来
シンセティックデータは、プライバシー保護とイノベーション促進という一見相反する課題を両立させる重要な技術として、今後ますます存在感を増していくでしょう。特にAI開発の加速と普及において、シンセティックデータは不可欠な要素となっています。
2025年現在、シンセティックデータ革命はまだ始まったばかりです。技術の発展と共に、より高品質で多様なシンセティックデータの生成が可能になり、応用領域も拡大していくことでしょう。データドリブンな意思決定を目指す企業や組織にとって、シンセティックデータの戦略的活用は競争優位性を確保する重要な手段となるはずです。
プライバシー、データ量、コスト、品質のバランスを取りながら、シンセティックデータを活用したデータ戦略の構築が今後の成功の鍵となります。皆さんの組織でも、シンセティックデータの可能性を検討してみてはいかがでしょうか。
参考・引用元
- Gartner、2025年のデータ/アナリティクスのトップ・トレンドを発表
- 合成データ市場の規模とシェア分析 – Mordor Intelligence
- AIのための合成データ – MIT Tech Review
- 合成データにより加速するデータ利活用 – PwC
- 合成データが製品テストを革新:イプソスが語る効率的な市場調査
- 合成データとは何か? 生成AIとの関係は? – ビジネス+IT
- 「プライバシー保護合成データ」でヘルスケアデータ活用を加速 – 日鉄ソリューションズ
- 技術】合成データアルゴリズム GAN – Acompany
- 合成データとは – 統計的な有用性を維持する架空のパーソナルデータ – LayerX
- 合成データとは何か? – AWS





コメント